최근 이미지 분석과 관련하여 관심이 많아져서 실습한 내역을 작성해 봅니다.
허접하게나마 테스트해 본 내역이지만 블로그 등을 참조하기에는 시행착오들이 다들 있으시기 때문에 따라서 해보시면 좋을 듯 합니다.
이미지 분석과 관련된 오픈소스나 이런 것을 활용하면 되지만, 그래도 가장 우수하게 인식되는 기술을 사용해 보고 어느정도 이미지를 인식하고 정보를 추출하는지를 알아보기 위한 테스트이니 참고하세요~
먼저 해당 API는 Goggle 계정을 기반으로 하기 때문에 Google 계정이 있어야 합니다.
계정이 없다면 Console 연결 페이지에 로그인 창이 연동되는 그 때 생성하시면 됩니다.
먼저 GCP 메인 페이지로 접속 합니다.
https://console.cloud.google.com/
Google Cloud Platform
하나의 계정으로 모든 Google 서비스를 Google Cloud Platform을 사용하려면 로그인하세요.
accounts.google.com
1. 접속을 하셨으면 먼저 프로젝트를 생성해야 합니다.
메인 페이지 상단에 보면 아래 그림의 빨간색으로 표시된 부분을 클릭하면 프로젝트를 선택하는 팝업이 뜹니다.
저는 프로젝트명을 VisionApiTest로 생성했습니다.
이는 사용자에 맞는 명칭으로 진행하시면 됩니다.
2. 프로젝트를 설정 하셨으니, 다음은 프로젝트에 사용되어야 할 API를 해당 프로젝트에 사용 설정 합니다.
- API 설정 화면으로 이동하시려면 좌측 상단에 있는 햄버거버튼을 누르면 "API 및 서비스" 메뉴가 보이니 그 메뉴를 클릭해서 이동하시면 됩니다.
- API 및 서비스로 이동해서 아래 그림과 같이 API 및 서비스 사용 설정을 누릅니다.
- 설정을 누르면 아래와 같이 검색할 수 있는 화면이 나옵니다. 여기서 Vision API를 검색해봅니다.
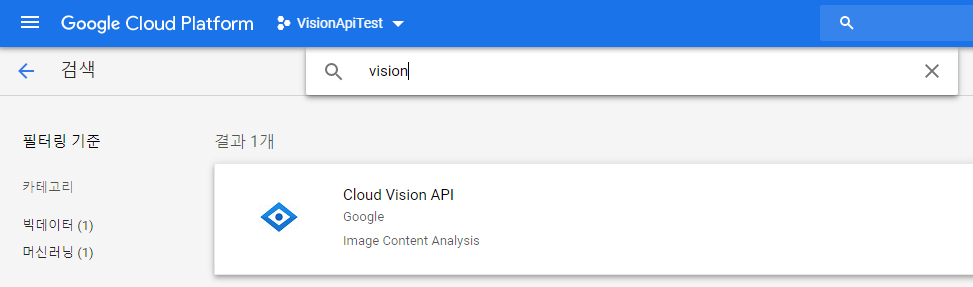
- "API 사용해 보기"를 클릭하여 해당 프로젝트에 API 사용 설정 하기

저의 경우는 하단에 "요청한 API를 사용할 수 있는 권한이 없습니다."라고 떴으나, 수행상에는 문제가 없었습니다.
이 내용도 참고하세요~
3. API설정을 끝냈으니, 서비스 계정을 만들고 권한을 부여합니다.
- 햄버거 버튼을 눌러 IAM 및 관리자 > 서비스 계정으로 이동합니다.
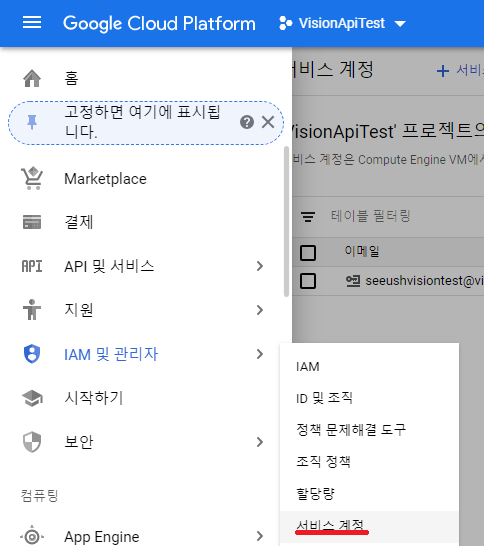
- "서비스 계정 만들기"를 클릭합니다.
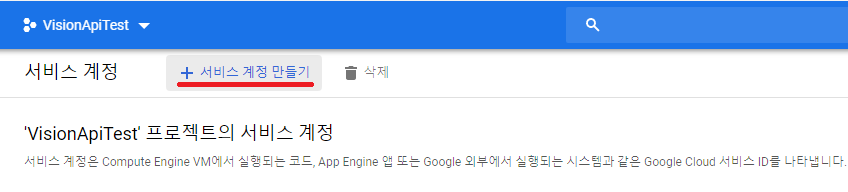
- "서비스 계정 이름" 만 입력을 하고 만들기를 누릅니다.
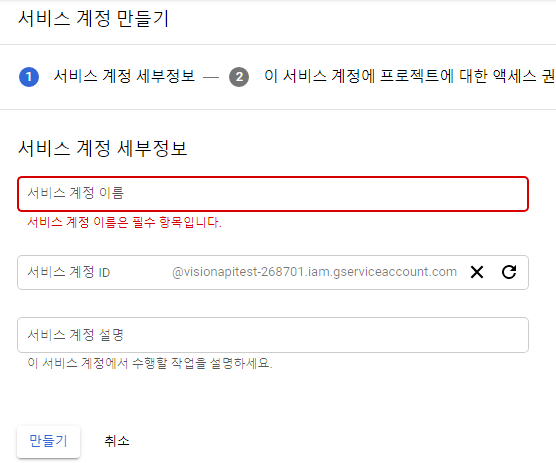
- 서비스 계정 권한에 대한 역할을 설정합니다. (프로젝트 > 소유자)
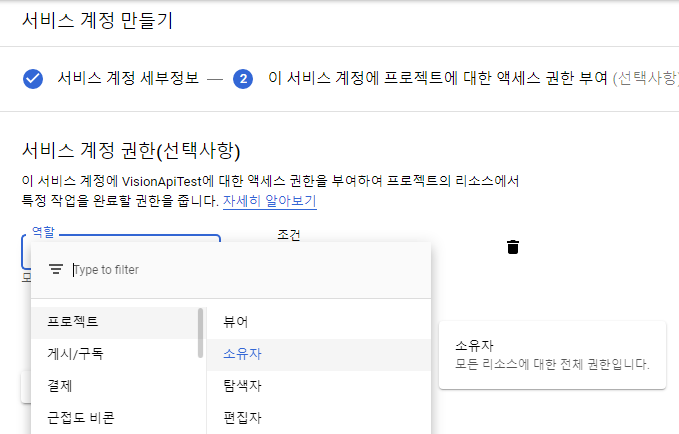
- 어플리케이션에서 사용할 키를 만들고 PC에 저장합니다. (JSON)

4. 저장된 키를 어플리케이션에 사용 할 수 있게 환경변수로 설정합니다.
윈도우터미널(cmd)로 아래 내역을 실행합니다.
- set GOOGLE_APPLICATION_CREDENTIALS=D:\VisionAPI\VisionApiTest-2dac831ec84b.json
5. Python 설치
D:\VisionAPI>pip install --upgrade google-cloud-vision

6. Python 프로그램 개발 (quickstart.py)
import io
import os
# Imports the Google Cloud client library
from google.cloud import vision
from google.cloud.vision import types
# Instantiates a client
client = vision.ImageAnnotatorClient()
# The name of the image file to annotate
file_name = os.path.join(
os.path.dirname(__file__),
'resources/wakeupcat.jpg')
# Loads the image into memory
with io.open(file_name, 'rb') as image_file:
content = image_file.read()
image = types.Image(content=content)
# Performs label detection on the image file
response = client.label_detection(image=image)
labels = response.label_annotations
print('Labels:')
for label in labels:
print(label.description)
여기서 주의할 사항은 이미지를 읽어들일 디렉토리에 분석할 이미지 파일이 있어야 한다.
동일한 프로젝트 경로 하단에 resources/wakeupcat.jpg 있어야 한다.
관련 경로 및 파일명은 사용자에 맞게 변경을 하면 된다.
> 경로 및 파일이 없을 경우 아래와 같이 애러가 발생한다. (File not found error)

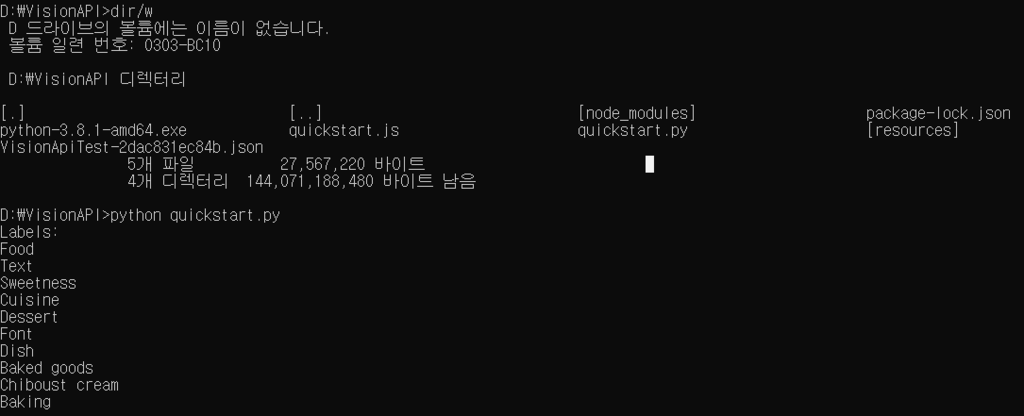
7. 개발한 프로그램을 실행한다. (python quickstart.py 로 실행)
Labels : Food Text Sweetness /Cuisine /Dessert /Font /Dish /Baked goods /Chilboust cream /Baking
>> 그림에 대한 설명류가 추출 됨
※ 테스트 한 이미지 샘플

8. 이미지에 있는 Text를 추출하기 위해 프로그램 수정 및 수행
- label을 text로 변경 후 재수행 (텍스트 추출)
# Performs label detection on the image file
response = client.text_detection(image=image)
labels = response.text_annotations
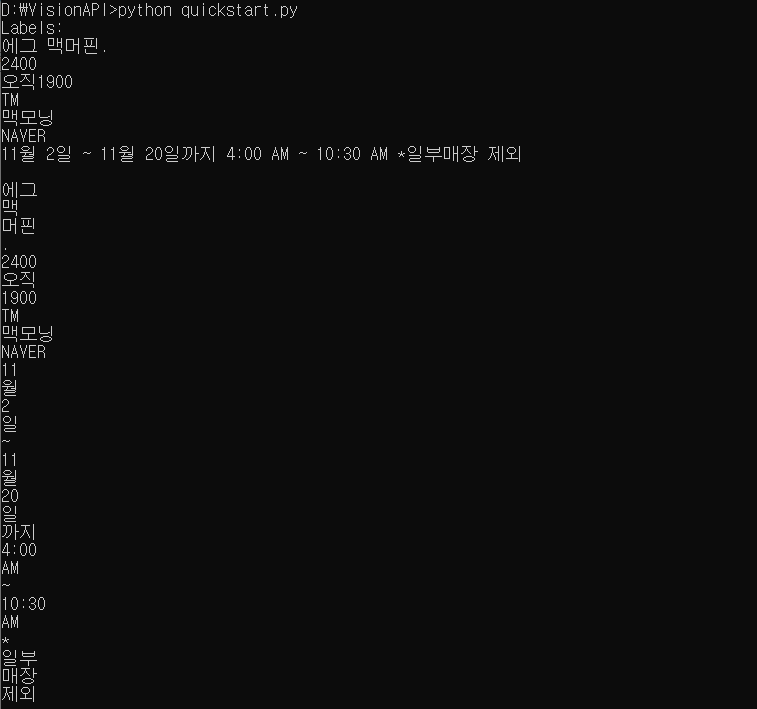
9. 영수증 이미지 테스트

촬영한 영수증 정보까지 인식이 잘 된다.
이로서 실습 끝~~